

【導(dǎo)讀】IPS體系結(jié)構(gòu)中的系統(tǒng)控制協(xié)處理器簡稱CP0,專門提供指令正常執(zhí)行所需的環(huán)境,進(jìn)行異常/中斷處理、高速緩存填充、虛實(shí)地址轉(zhuǎn)換、操作模式轉(zhuǎn)換等操作。單從硬件的角度而言,系統(tǒng)控制協(xié)處理器對指令集的作用就相當(dāng)于操作系統(tǒng)對應(yīng)用程序的作用一樣。
異常處理
CPU運(yùn)行過程中常常需要中斷正常執(zhí)行的指令流程,跳轉(zhuǎn)去執(zhí)行某段特殊的指令段,接著再恢復(fù)原來的指令序列。MIPS體系結(jié)構(gòu)中稱這樣的過程為異常(Exception)。所有的異常都采用統(tǒng)一的機(jī)制處理。

對于異常情況,需要采取以下3方面的措施:
1.異常檢測:CPU需要及時(shí)檢測出哪個(gè)部件發(fā)生了什么異常;一般而言,異常檢測由各個(gè)模塊進(jìn)行,如加法溢出由加法器在運(yùn)算過程中產(chǎn)生,并在相應(yīng)的流水段被系統(tǒng)控制協(xié)處理器CP0讀入。因此這部分功能不屬于CP0的設(shè)計(jì)范圍。
2.異常處理:CPU按照優(yōu)先級選擇哪個(gè)異常被處理,并進(jìn)行必要的上下文切換(Context Switch),為進(jìn)入異常服務(wù)子程序做準(zhǔn)備,保證與該種異常對應(yīng)的服務(wù)程序被執(zhí)行,并且能夠從中斷處完全恢復(fù)原來的指令執(zhí)行現(xiàn)場。
3.異常服務(wù):執(zhí)行異常服務(wù)子程序,這部分主要由軟件(操作系統(tǒng))來完成。
對異常處理機(jī)制的要求
與傳統(tǒng)的異常/中斷處理機(jī)制相比,在MIPS 4Kc體系結(jié)構(gòu)下的異常處理需要特別考慮3個(gè)因素。
流水線的劃分
本設(shè)計(jì)采用五段流水線設(shè)計(jì),即每條指令的執(zhí)行一般都經(jīng)過IF(取指)、DE(指令譯碼)、EX(指令執(zhí)行)、MEM(訪問存儲(chǔ)器)和WB(數(shù)據(jù)寫回R.F.)五個(gè)步驟。因?yàn)橹噶顒?dòng)作被分割,所以異常源也被分割到各個(gè)流水線段。例如:加法溢出異常只能在EX被檢測到。
精確異常處理機(jī)制
精確異常處理是指在發(fā)生異常時(shí),僅僅對發(fā)生異常的指令或其后面的指令進(jìn)行異常處理;而其前面的指令要保證能夠正常結(jié)束。所謂“精確”,是指受到異常處理影響的只有產(chǎn)生異常條件的那條指令,所有在此之前的指令在異常被處理前都將被執(zhí)行完成。異常處理結(jié)束后仍將從發(fā)生異常的指令開始繼續(xù)執(zhí)行。
操作模式切換
對于多進(jìn)程操作系統(tǒng),至少要區(qū)分兩種進(jìn)程:有特權(quán)的操作系統(tǒng)“核心”進(jìn)程和一般程序的“用戶”進(jìn)程。當(dāng)CPU檢測到異常發(fā)生時(shí),指令執(zhí)行的正常順序會(huì)被暫停,處理器進(jìn)入核心模式。當(dāng)異常服務(wù)子程序執(zhí)行完后,CPU從斷點(diǎn)中恢復(fù)現(xiàn)場,繼續(xù)執(zhí)行原指令序列。
異常處理流水線
根據(jù)上述分析可以確定,硬件異常處理流水線的主要任務(wù)有3個(gè):更新相應(yīng)的CP0寄存器,即寫CP0寄存器;保存發(fā)生異常的指令地址,或當(dāng)異常指令在延遲槽時(shí),保存引起延遲槽的跳轉(zhuǎn)指令地址;選擇異常服務(wù)子程序的入口地址。
CP0寄存器記錄了CPU當(dāng)前的狀態(tài),因此,對CP0寄存器的寫就是對CPU狀態(tài)的改變,需要進(jìn)行嚴(yán)格的控制。而且對寄存器的寫是影響關(guān)鍵路徑的主要因素。因此本文主要論述對CP0寄存器寫操作的設(shè)計(jì)。
每個(gè)寄存器或寄存器某些位的寫操作都是由一個(gè)或一組異常事件是否發(fā)生而決定的。為此每一個(gè)流水段產(chǎn)生并被接收的異常都將被編碼,稱為異常編碼,并在段與段之間進(jìn)行傳遞,直到MEM段。在MEM段,異常編碼被用于產(chǎn)生對CP0寄存器的寫使能信號,需要進(jìn)行復(fù)雜的解碼使MEM段變長,這成為提高整個(gè)CPU速度的瓶頸。為了減少這個(gè)瓶頸,可增加專門用于產(chǎn)生寫使能信號的邏輯。每一級流水線產(chǎn)生的異常直接產(chǎn)生寫使能,并經(jīng)過簡單的優(yōu)先級比較,不管它是由哪個(gè)異常類型產(chǎn)生的,均產(chǎn)生1位的寫使能信號。那么,在MEM段就可以避免復(fù)雜的解碼,直接產(chǎn)生對相關(guān)CP0寄存器的寫使能信號。這一方案采用了以空間換時(shí)間的方法:縱向的執(zhí)行時(shí)間減少了,而橫向則需要增加寫使能判別邏輯。增加邏輯功能意味著需要占用更多的芯片面積,考慮到CP0模塊處于整個(gè)CPU的邊緣,而且全定制物理設(shè)計(jì)可以大大縮減芯片面積,因此該方案具有可行性。
系統(tǒng)控制協(xié)處理器的全定制物理設(shè)計(jì)
在深亞微米級的集成電路芯片里,器件(晶體管)本身對時(shí)延的貢獻(xiàn)已越來越小,主要延遲在于連線延遲。由于CP0功能的特殊性,它和存儲(chǔ)管理單元 MMU、指令計(jì)數(shù)單元PC都有很多連線,這些連線很可能處于全芯片的關(guān)鍵路徑上;而且由于CP0邏輯比較復(fù)雜,按照標(biāo)準(zhǔn)單元法自動(dòng)布局布線生成的模塊自身面積就很大,某些連線在CP0內(nèi)部就要走很多彎路,可能造成很大的延時(shí)。所以決定采用全定制方法設(shè)計(jì)CP0的數(shù)據(jù)通路,以方便控制連線的走向和布局。
控制通路與數(shù)據(jù)通路的劃分
數(shù)字電路系統(tǒng)的正常運(yùn)作過程中存在數(shù)據(jù)流(包括一般意義上的數(shù)據(jù)、指令和地址)和控制流。而數(shù)據(jù)流和控制流是相對獨(dú)立的:數(shù)據(jù)流實(shí)現(xiàn)的邏輯相對簡單,但有很多位數(shù)據(jù)并行;而控制流的邏輯較復(fù)雜,絕大多數(shù)是1位或幾位的控制信號。因此,控制通路一般不采用全定制設(shè)計(jì);而數(shù)據(jù)通路的全定制設(shè)計(jì)就具有高性能、低功耗、低成本的優(yōu)勢。
協(xié)助TLB進(jìn)行虛實(shí)地址轉(zhuǎn)換是CP0的主要功能之一。TLB屬于系統(tǒng)的特權(quán)資源,只有CP0有權(quán)對其進(jìn)行訪問,因此CP0與TLB之間的連線較多,數(shù)據(jù)交換的時(shí)延也比較關(guān)鍵。同時(shí),PC模塊與CP0的數(shù)據(jù)交換也非常重要。因此,CP0單元在版圖上最好同時(shí)靠近TLB和PC模塊。本設(shè)計(jì)將CP0中與TLB相關(guān)的邏輯與寄存器獨(dú)立為CP0T,放在MMU與PC模塊之間;CP0的其余部分歸為CP0E,放在PC下部,也就是整塊芯片的最下端。如下圖所示。
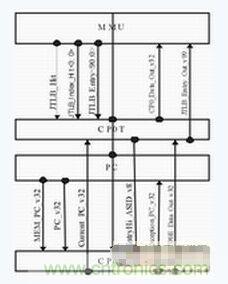
CP0單元與臨近單元的連接示意圖
電路設(shè)計(jì)
本設(shè)計(jì)中使用的電路輸入工具為Cadence公司的Composer。設(shè)計(jì)時(shí),將HDL描述轉(zhuǎn)化為電路描述后輸入到Composer中。然后,通過形式驗(yàn)證來確保所設(shè)計(jì)的電路與RTL代碼一致。電路設(shè)計(jì)的好壞很大程度上要取決于設(shè)計(jì)者的經(jīng)驗(yàn)和技巧。
電路的定制設(shè)計(jì)主要指的是,在Composer環(huán)境中手工設(shè)計(jì)晶體管級的電路。電路參數(shù)的確定由Synopsys的電路仿真工具Hspice協(xié)助完成。將從設(shè)計(jì)好的電路中抽出的網(wǎng)表輸入到Hspice中,仿真計(jì)算出電路的時(shí)延,再根據(jù)時(shí)延來修改電路MOS管的參數(shù)。
為了減少全定制設(shè)計(jì)的工作量,電路設(shè)計(jì)要建立模塊的微體系結(jié)構(gòu)。其中CP0的基本單元確定如下:基本的CP0寄存器(時(shí)鐘上沿同步寄存器) ;32位比較器;32位加法器;多選一選擇器(包括2選1、3選1和4選1 MUX);驅(qū)動(dòng)器(即反相器;其尺寸參數(shù)化以適應(yīng)不同驅(qū)動(dòng)要求)。
加法器基本采用了超前進(jìn)位加法器的思想,然后在整體上分成兩個(gè)16位加法器的模塊,模塊間采用進(jìn)位選擇加法器的思想,從而大大提高了整個(gè)電路的速度。但其面積比全部采用超前進(jìn)位加法器時(shí)要大20%左右。
設(shè)計(jì)出來的電路邏輯是否正確,時(shí)延是否滿足要求,分別需要做功能驗(yàn)證和電路仿真。在驗(yàn)證了各個(gè)小模塊的正確性之后,需驗(yàn)證小模塊之間的邏輯連接正確性,最后對整個(gè)模塊進(jìn)行驗(yàn)證,進(jìn)一步分析電路找出模塊中的最長路徑,通過仿真、更改電路、再仿真的過程,來確定該模塊是否能達(dá)到預(yù)期的邏輯設(shè)計(jì)要求。
版圖的全定制設(shè)計(jì)
版圖設(shè)計(jì)是根據(jù)電路功能和性能的要求以及工藝條件的限制(如線寬、間距、制版設(shè)備所允許的基本圖形等),設(shè)計(jì)集成電路制造過程中必需的光刻掩膜版圖。版圖設(shè)計(jì)與集成電路制造工藝技術(shù)緊密相連,是集成電路設(shè)計(jì)的最終目標(biāo)。
在設(shè)計(jì)過程中,為了降低設(shè)計(jì)的復(fù)雜度,采用混合設(shè)計(jì)模式,即全定制和標(biāo)準(zhǔn)單元設(shè)計(jì)相結(jié)合的設(shè)計(jì)方法。這樣既有利于保證電性能的要求,又能減小設(shè)計(jì)周期,是一種較為理想的設(shè)計(jì)模式。
在全定制版圖中,設(shè)計(jì)過程分為兩步完成,每個(gè)大單元電路總是由各種基本電路組合而成,所以第一步是繪制基本電路的版圖,畫完后做DRC和LVS,保證基本電路的正確性。第二步用這些基本電路來組合成大的單元。

全定制芯片設(shè)計(jì)可以根據(jù)數(shù)據(jù)通路電路的規(guī)則手工設(shè)計(jì)出合理的版圖。版圖設(shè)計(jì)中盡量保證各個(gè)部分的規(guī)整和對稱,使其易于擴(kuò)展。版圖的布局中使聯(lián)系較多的單元盡量靠近,從而縮短互連線的長度,減小每個(gè)單元的面積和時(shí)延,降低器件的負(fù)載電容,采取的具體措施如下:
1. 增加地與襯底、電源與阱的接觸,在沒有器件和走線的空白處多打接觸孔,并且將其與電源或地連接,有利于收集噪聲電流、穩(wěn)定電位、減小干擾和被干擾;
2.形成網(wǎng)狀的電源地線網(wǎng)絡(luò);
3.避免同層或上下兩層中長金屬線的平行走線,對噪聲敏感的線盡量布得短;
4.避免首尾循環(huán)的走線;
5.在滿足設(shè)計(jì)規(guī)則的前提下,盡量減小MOS管的有源區(qū)面積,以減小寄生電容,提高工作速度;
6.在數(shù)據(jù)通路設(shè)計(jì)中,要為金屬連線留下一些備用位置。
控制通路與數(shù)據(jù)通路的集成設(shè)計(jì)及驗(yàn)證
邏輯層次
控制部分直接用行為級的RTL代碼,數(shù)據(jù)通路部分由從全定制電路導(dǎo)出的結(jié)構(gòu)化RTL代碼,得到全模塊的邏輯描述。
可采用向量進(jìn)行驗(yàn)證,與采用RTL(或C模型)進(jìn)行驗(yàn)證的結(jié)果(trace文件)進(jìn)行比對。
電路層次
電路層次控制通路與數(shù)據(jù)通路的集成可以借助Composer順利完成。
對于延時(shí)信息的獲取,數(shù)據(jù)通路或控制通路內(nèi)部的路徑分別采用Hspice仿真及綜合來獲得,分析內(nèi)部是否存在關(guān)鍵路徑。
涉及數(shù)據(jù)通路與控制通路之間的關(guān)鍵路徑,可以由全定制部分提交數(shù)據(jù)通路部分接口的輸入/輸出時(shí)延信息,即該路徑在其內(nèi)部需要的時(shí)間。以這些信息作為外部約束,再對相關(guān)模塊進(jìn)行綜合(按模塊綜合),結(jié)果文件中將得到集成后的關(guān)鍵路徑。
版圖層次
要保證版圖與電路的一致性,需要做LVS驗(yàn)證。即將控制通路的門級網(wǎng)表導(dǎo)入Composer,與數(shù)據(jù)通路的全定制電路合成總電路,并由此提取電路級的Spice網(wǎng)表進(jìn)行LVS驗(yàn)證。LVS采用的工具為Mentor Graphics 的Calibre工具。
結(jié)語
本文主要研究了基于MIPS 4Kc體系結(jié)構(gòu)的系統(tǒng)控制協(xié)處理器的設(shè)計(jì)和實(shí)現(xiàn),包括精確異常處理的實(shí)現(xiàn)方式和全定制的物理設(shè)計(jì)。在對精確異常處理機(jī)制的過程中通過增加寫使能判別邏輯達(dá)到了縮減關(guān)鍵路徑時(shí)延的目的,降低了控制邏輯的復(fù)雜性,同時(shí)增加了全芯片的可靠性。本文的設(shè)計(jì)通過了邏輯、電路驗(yàn)證,應(yīng)用于32位CPU的設(shè)計(jì)中,并采用中芯國際的1P6M 0.18mm工藝成功流片。


